As a Natural Language Processing (NLP) practitioner there are many activities that are needed across the NLP pipeline in order to develop a solution that is fit-for-purpose.
Picking the wrong transformer model for an NLP task can have several repercussions, including:
- Poor performance: The most obvious consequence of picking the wrong transformer model is poor performance on the NLP task. Different transformer models have different strengths and weaknesses and choosing the wrong one can lead to suboptimal results.
- Overfitting or underfitting: If the chosen transformer model is too complex for the task, it may overfit the data, meaning that it performs well on the training set but poorly on the test set. On the other hand, if the chosen transformer model is too simple, it may underfit the data, meaning that it fails to capture the nuances of the task.
- Longer training time: If the chosen transformer model is too large or complex, it may require longer training time, which can be costly and time-consuming.
- Difficulty in fine-tuning: Fine-tuning a transformer model involves adapting it to a specific task and dataset. If the chosen transformer model is not suitable for the task, fine-tuning may be difficult or impossible.
- Poor interpretability: Different transformer models use different architectures, and some may be more interpretable than others. Choosing a transformer model that is difficult to interpret can make it harder to understand why it is making certain predictions, which can be a problem in applications where transparency is important.
In this article we shall discuss techniques on how best to ensure the best performance at the shortest time possible to fin-tune a model with proper fitment based on the NLP activities performed.
Text Classification with DeBERTa
Text Classification is the task of assigning a sentence or document an appropriate category. The categories depend on the chosen dataset and can range from topics.
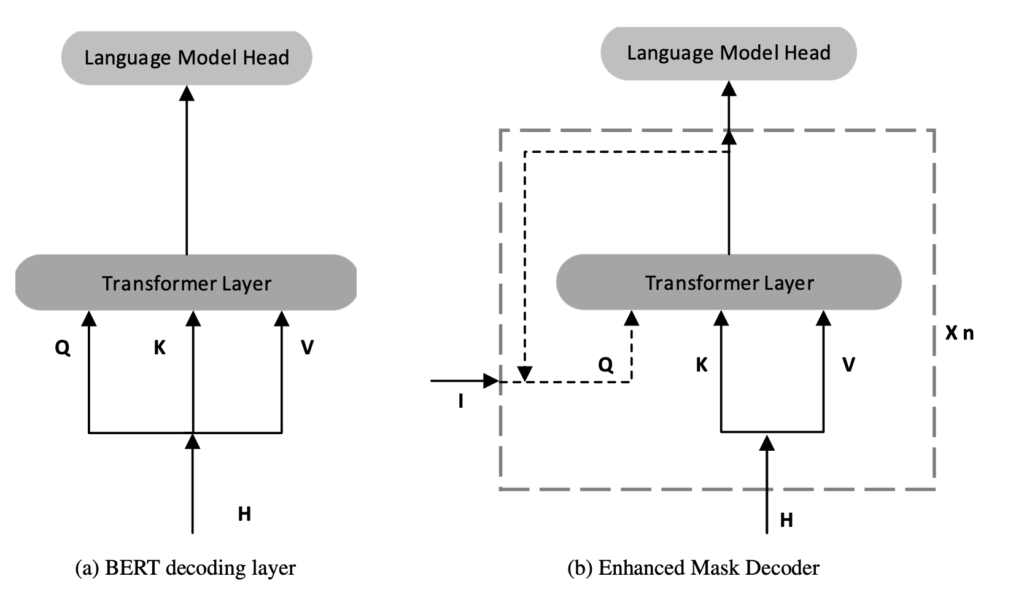
DeBERTa (figure b) is one of the best performing Transformer-based neural language models for text classification natural language processing (NLP) methodologies.
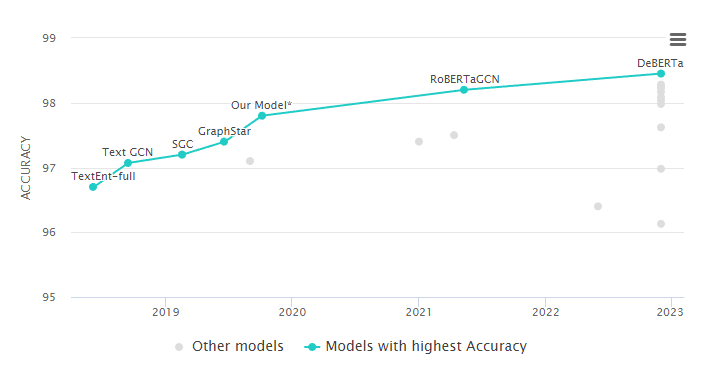
DeBERTa that aims to improve the BERT (figure a) and RoBERTa.
Classifier Confidence Calibration
Classifier Confidence calibration in NLP refers to the process of ensuring that the confidence scores assigned by a machine learning model to its predictions are calibrated or well-calibrated, meaning that the predicted probabilities accurately reflect the true likelihood of a given outcome.
One common technique for ensuring confidence calibration in NLP is to use probability calibration methods, such as Platt scaling or isotonic regression. These methods involve training an additional model or function that takes the output of the original model and maps it to a calibrated probability score. Another approach is to use ensembling methods, where multiple models are combined to improve calibration and reduce prediction errors.

In NLP, confidence calibration is particularly important in applications where the model’s predictions are used to make decisions that have real-world consequences, such as in medical diagnosis or legal decision-making (confidence scores).
Final Thoughts
If you help in selecting the best Transformer models withing your NLP pipeline, why not reach out to the team at Jivoo today?